
优化技术
优化技术
Prefill Cacheing 重要
如果新一轮的 prompt 能够直接复用上一轮计算得到的 KV Cache,就能实现跨请求的 KV Cache 复用,从而显著提升 prefill 的性能,并降低新一轮请求的首次 Token 计算时间(Time To First Token,TTFT)。这种优化方法被称为 Prefix Caching,其核心思想是缓存系统提示和历史对话中的 KV Cache,以便在后续请求中复用,从而减少首次 Token 的计算开销。
Prefill matching 在vLLM和 Sglang分别是怎么实现的?
SGLang 通过 RadixAttention 来实现 Prefix Caching,其实现的关键点如下:
- 每次请求结束后,当前请求中的 KV Cache 不会立即丢弃,而是通过 RadixAttention 算法将其保留在 GPU 显存中。RadixAttention 算法还将序列 token 与 KV Cache 之间的映射关系保存在 RadixTree 数据结构中。
- 当新的请求到达时,SGLang 的调度器通过 RadixTree 进行前缀匹配,判断新请求是否能够命中缓存。如果命中缓存,调度器将复用已有的 KV Cache 来处理该请求。
- 由于 GPU 显存资源有限,缓存中的 KV Cache 不能无限期保留,因此需要设计相应的逐出策略。RadixAttention 采用的逐出策略是 LRU(Least Recently Used,最近最少使用),这一策略与操作系统中的 LRU 页面置换算法非常相似。具体的逐出流程可参见 SGLang 的论文,其中有详细描述。
在 vLLM 中,Prefix Caching 使用的是 RadixAttention 算法,但是采用哈希(hash)码作为物理 KV Block 的唯一标识,这种实现方式较为简洁,且工程上更易操作。我们暂且将这种实现称为 Hash RadixAttention。所有当前 KV Block 的哈希码依赖于此前所有 KV Block 的 token_ids,因此,这个唯一的哈希码实际上也代表着一种唯一的前缀关系。
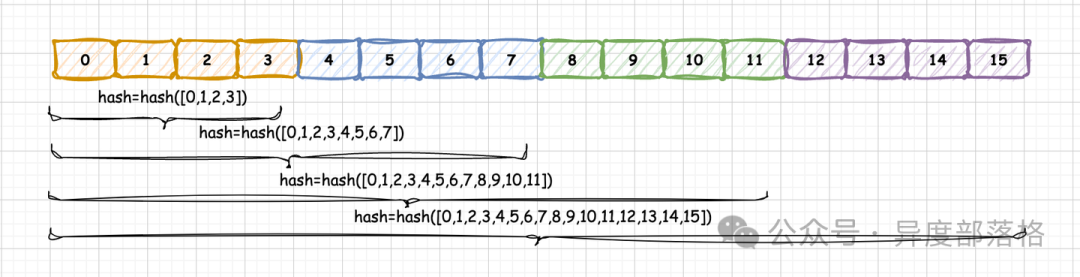
能不能从中间开始匹配prefix?
KV Cache(记忆)是按顺序生成的:模型处理“法国的首都是巴黎”这句话时,就像演员念台词。念“法国”的时候,产生关于“法国”的记忆;念“首都”的时候,产生关于“首都”的记忆,但这个记忆是基于前面有“法国”这个上下文才成立的。记忆是环环相扣、按顺序累积的。KV Cache 是高度依赖上下文的连续记忆。必须从头开始,连续匹配。
Chunked Prefill 了解
Chunked Prefill 着眼于解决长上下文带来的调度与延迟问题。 传统上,一个长提示词的预填充计算(一个非常庞大的矩阵乘法)必须一次性在GPU上完成,这会独占GPU较长时间,阻塞后续解码(Decode)步骤的执行,导致已生成部分的输出卡顿,用户体验上出现“明明生成了几个词,却长时间停顿”的现象。Chunked Prefill 将该大型的预填充计算切分成多个较小的“块”顺序执行。关键优化在于,它在每个计算块完成后,就立即调度执行一次或多次解码步骤,然后再处理下一个预填充块。这种“预填充-解码”的交错流水线,极大地平滑了计算资源的使用,大幅降低了首次解码和后续解码的延迟,保障了流式输出的即时性与流畅性。它解决的是长上下文预填充导致的调度阻塞和响应延迟问题。